Care-giving Training Assistant Robot (CaTARo)
Background
Japan is facing one of the most rapid aging trends in the world, with nearly 30% of its population aged 65 or older. This demographic shift is creating unprecedented demand for healthcare services, while simultaneously exacerbating shortages of medical professionals and caregivers. Traditional training methods alone are no longer sufficient to prepare enough skilled personnel to meet the complex medical and caregiving needs of an aging society. In this context, simulated patient robots offer a critical solution by providing realistic, repeatable, and safe training environments.
Unlike human actors or mannequins, these robots can consistently reproduce a wide range of physical and behavioral symptoms, enabling healthcare trainees to practice and refine their skills without risk to real patients. Moreover, by incorporating sensors and data-driven feedback, simulated robots can objectively assess trainee performance, helping to standardize education quality and accelerate the development of clinical competence.
Physical Robot for Rehabilitation Exercise
CaTARo features motorized arms that can replicate human-like movements, allowing trainees to practice range-of-motion exercises and other physical interactions. The robot’s head unit includes a 3D facial avatar capable of expressing pain levels, which is projected onto a facial mask to provide visual feedback.
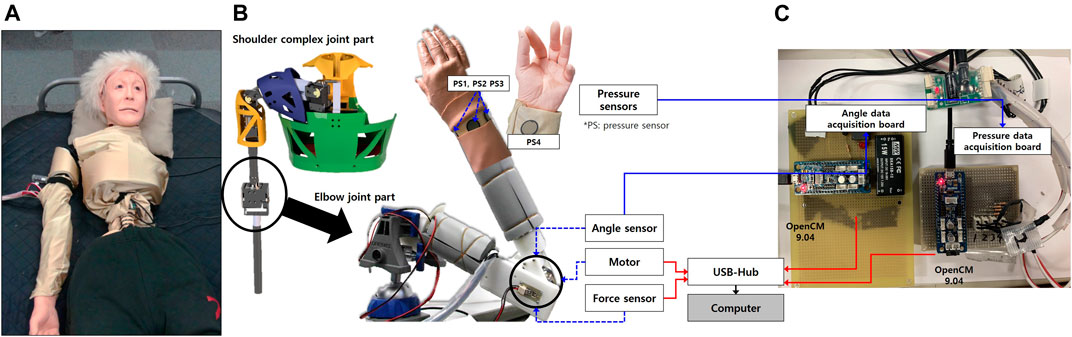

CaTARo’s shoulder complex is designed with multiple degrees of freedom to replicate the intricate movements of the human shoulder. This includes the glenohumeral and sternoclavicular joints, enabling realistic simulations of various arm motions essential for caregiver training.
The robot employs high-precision servo motors, such as the MX-28 from Robotics Inc., to drive its joints. These actuators provide the necessary torque and control to mimic human-like movements accurately.
Hardwares
- Servo motors: MX-28
- Sensors
- Angle sensor: SV01L103AEA11T00
- Force sensor: CFS018CA201
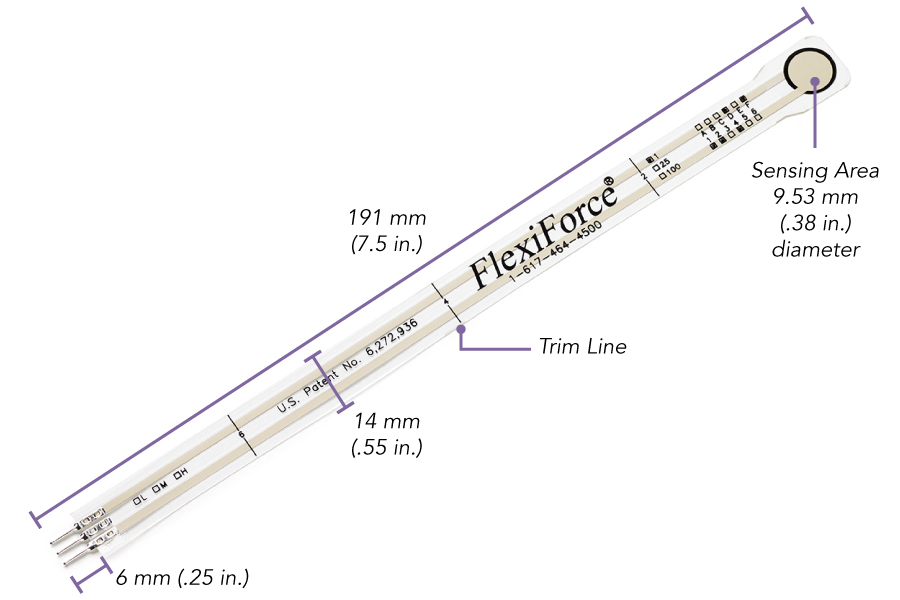
- 4 x FlexiForce A201
Simulated Patient Avatar
By utilizing data-driven models and real-time feedback mechanisms, the avatar can mimic expressions associated with pain, discomfort, or other emotional states, providing trainees with a more immersive and authentic learning experience. Such realistic simulations are crucial for developing empathy, improving diagnostic skills, and preparing healthcare providers for real-world patient interactions.
Our research provides experimental solutions for both virtual and physical environments.
A. Mixed Reality
The integration of Virtual Reality (VR) with robotic limbs offers a powerful platform for immersive medical training. In this system, the robot’s physical limbs are synchronized with a virtual avatar in a pre-designed interactive scenario, allowing trainees to practice procedures in a highly controlled and responsive environment.
As the robot moves, its joint data is streamed to update the avatar in real time, ensuring that physical performance is accurately mirrored in the virtual environment. By combining physical embodiment with VR-based contextual training, this approach enhances skill acquisition, procedural accuracy, and trainee confidence, while providing a safe, repeatable, and measurable environment critical for preparing healthcare providers.

B. Physical Embodiement

1. Back-projection Display
CaTARo features a 3D facial avatar system that projects expressions onto a facial mask. This system utilizes data from the UNBC-McMaster Pain Archive and a fuzzy logic–based evaluation method to display real-time pain expressions, enhancing the realism of training scenarios.
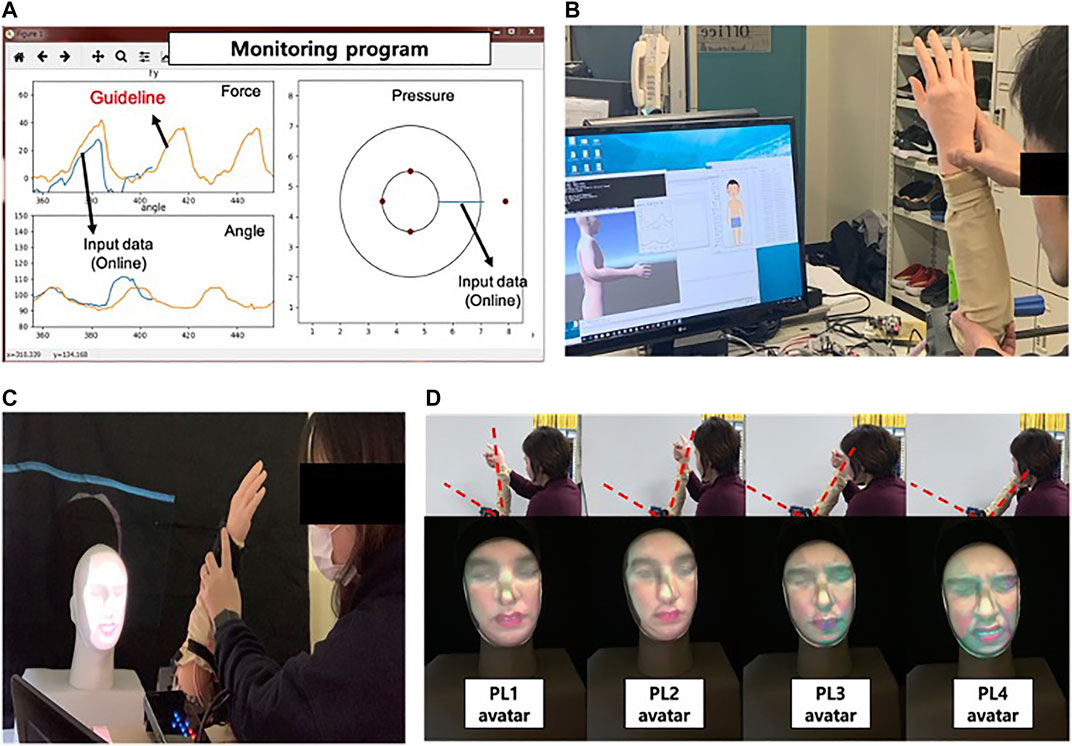
2. Hyper-realistic 3D Gaussian Avatar
By employing a mesh priori, we trained a 3D Gaussian Splatting-based avatar that synthesizes facial animation in real-time. The facial expression can be transferred and control through FLAME parameters that constructs the prior mesh. However, as the expression spaces differ across subjects, we are also researching how to disentangle the universal and unique expression space to better capture human facial expression.

3. Holographic Avatar
VR headset allows immersive experience to simulated training session with limitation to one user at a time. Holographic display elevates this issue by projecting 3D volumetric visual to multiple subjects at the same time.
With customized CUDA’s kernel and optimized OpenGL-based pipeline, we stream 3D Gaussian Avatar animation to 3D display in real-time according to user’s viewing angles.

Humanoid Facial Motion Modeling
Realistic data-driven behavior imitation skill is critical for simulated patients to achieve its goal. In our study, we analyzed human’s facial behaviors, especially non-verbal facial behavior to learn stochastic facial reaction that powers our humanoid robot’s facial behavior.
A. Generalized Non-verbal Facial Behavior
We represented humanoid face behavior as temporal change of 3D Morphable Model (3DMM) parameters while exploring this modality’s unique characteristics such as sparsity, continuity, and its correlation with other modality such as speech and visual signal of another human partner.
The model extracts controlling time steps from transitioning steps to learn when, why, and how human reacts to stimulation in dyadic conversation as a listener.
B. Painful Expression Behavior
To learn the relationship between pained expressions and pain intensity, we devised a generative learning model that predicts pained expression according to control signals such as pain intensity, emotional state, and tolerance.