介護トレーニング支援ロボット(CaTARo)
背景
日本は世界でも最も急速な高齢化を迎えており、65歳以上の人口が全体の約30%を占めています。
この人口動態の変化により、医療サービスに対する需要がかつてないほど高まる一方で、医療従事者や介護者の不足が深刻化しています。
従来のトレーニング方法だけでは、複雑な医療・介護ニーズに対応できる十分な人材を育成することが困難になっています。
このような状況において、模擬患者ロボットは、現実的かつ繰り返し可能で安全なトレーニング環境を提供する重要なソリューションとなります。
人間の俳優やマネキンとは異なり、これらのロボットは幅広い身体的・行動的症状を一貫して再現できるため、医療従事者の訓練生は、実際の患者にリスクを与えることなく技能を磨き、洗練することが可能です。
さらに、センサーやデータ駆動型フィードバックを組み込むことで、訓練生のパフォーマンスを客観的に評価でき、教育の質の標準化と臨床能力の向上を加速させることができます。
リハビリ訓練用物理ロボット
CaTARoは、人間のような動きを再現できるモーター駆動アームを搭載しており、訓練生は関節可動域訓練やその他の身体的インタラクションを実践できます。
ヘッドユニットには、痛みのレベルを表現できる3Dフェイシャルアバターが搭載されており、顔マスクに投影して視覚的フィードバックを提供します。
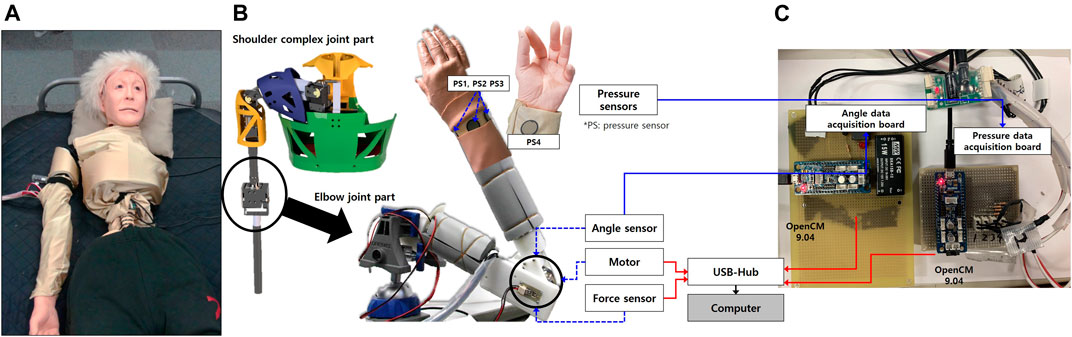

CaTARoの肩複合部は、多自由度設計により人間の肩の複雑な動きを再現できるよう設計されています。
肩甲上腕関節(glenohumeral joint)や胸鎖関節(sternoclavicular joint)を含み、介護訓練に必要な多様な腕の動作をリアルにシミュレーション可能です。
ロボットの関節駆動には、Robotics Inc.製のMX-28のような高精度サーボモーターを採用しています。
これらのアクチュエータは、人間らしい動きを正確に再現するために必要なトルクと制御性を提供します。
ハードウェア構成
- サーボモーター: MX-28
- センサー
- 角度センサー: SV01L103AEA11T00
- 力覚センサー: CFS018CA201
- フレキシフォースセンサー A201 ×4個
模擬患者アバター
データ駆動型モデルとリアルタイムフィードバック機構を活用することで、アバターは痛み、不快感、その他の感情状態を模倣し、訓練生により没入感のあるリアルな学習体験を提供します。
このようなリアリティのあるシミュレーションは、共感力の育成、診断スキルの向上、実際の患者対応能力の強化に不可欠です。
本研究では、仮想環境と物理環境の両方に対応した実験的ソリューションを提供しています。
A. 複合現実(Mixed Reality)
VR(バーチャルリアリティ)とロボットアームの統合により、没入型医療訓練のための強力なプラットフォームが構築されます。
本システムでは、ロボットの物理的な動きが事前設計されたインタラクティブな仮想シナリオと同期され、訓練生は高度に制御された環境下で手技を実践できます。
ロボットが動くたびに関節データがリアルタイムでアバターに反映され、仮想環境における動作の正確な再現が可能です。
物理的実体とVRベースの文脈的訓練を組み合わせることで、スキル習得、手技精度、訓練生の自信向上が促進され、安全かつ再現可能で測定可能な環境が提供されます。

B. 物理的実体化(Physical Embodiment)

1. 背面投影ディスプレイ(Back-projection Display)
CaTARoには、顔マスクに表情を投影する3Dフェイシャルアバターシステムが搭載されています。
このシステムは、UNBC-McMaster Pain Archiveのデータとファジィ論理に基づく評価手法を用い、リアルタイムで痛みの表情を再現し、トレーニングシナリオのリアリズムを向上させます。
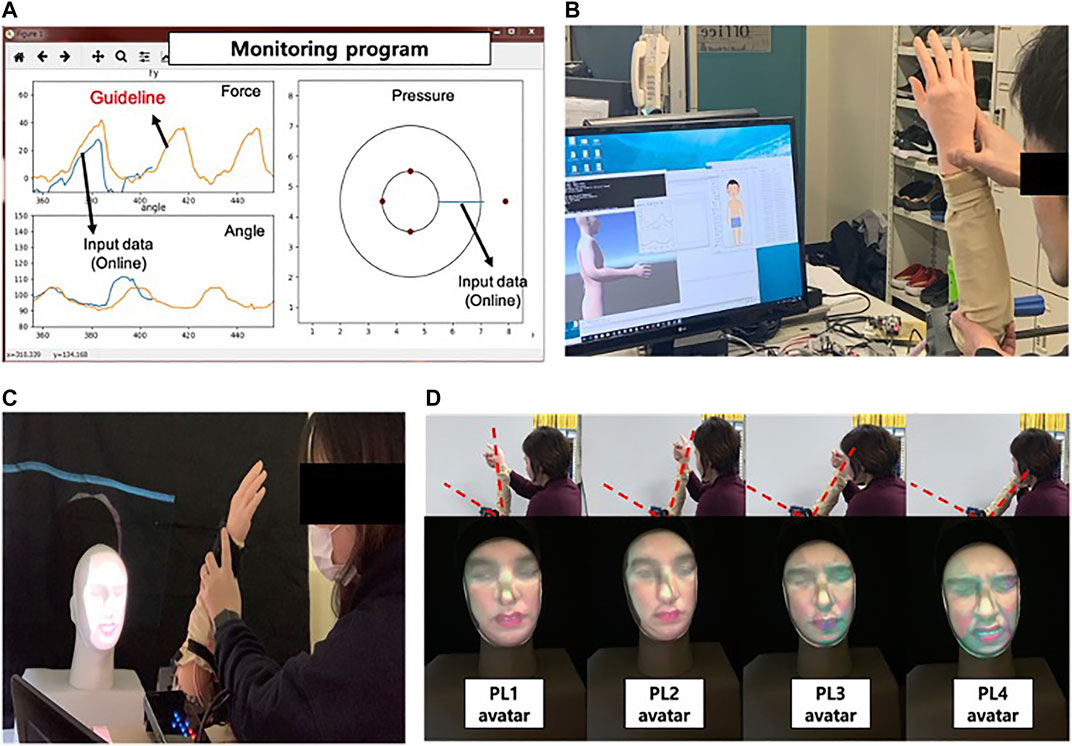
2. 超リアルな3Dガウシアンアバター(Hyper-realistic 3D Gaussian Avatar)
事前メッシュ(priori mesh)を用いて、リアルタイムで顔アニメーションを生成できる3D Gaussian Splattingベースのアバターを学習させました。
表情はFLAMEパラメータを通じて制御・転送されます。
ただし、被験者ごとに表情空間が異なるため、より人間らしい表情再現のため、共通表現空間と個別表現空間の分離に関する研究も進めています。

3. ホログラフィックアバター(Holographic Avatar)
VRヘッドセットは没入型体験を提供しますが、同時に一人しか利用できないという制約があります。
ホログラフィックディスプレイは、3Dボリューム映像を複数の人に同時に投影することで、この問題を解決します。
CUDAカーネルと最適化されたOpenGLパイプラインを活用し、ユーザーの視点角度に応じて3D Gaussianアバターアニメーションをリアルタイムで3Dディスプレイにストリーミングしています。

ヒューマノイド顔面動作モデリング
リアルなデータ駆動型行動模倣技術は、模擬患者ロボットが本来の目的を達成するために重要です。
本研究では、人間の非言語的顔面行動に着目し、リスナーとしての顔面反応パターンを学習し、ロボットの表情制御に応用しています。
A. 一般化された非言語顔面行動
ヒューマノイドの顔動作を3Dモーフィングモデル(3DMM)パラメータの時間変化として表現し、
スパース性、連続性、また他者の音声・視覚信号との相関など、このモダリティ特有の特性を分析しました。
モデルは、会話中に人間がどのタイミングで、なぜ、どのように反応するかを学習し、
適切なリスナー反応生成を実現します。
B. 痛み表現行動(Painful Expression Behavior)
痛み表現と痛み強度の関係性を学習するため、
痛み強度、感情状態、耐性といった制御信号に応じて痛み表現を予測する生成モデルを開発しました。